
Introdução
A arquitetura RAG (Retrieval-Augmented Generation), ou “geração aumentada por recuperação de dados”, representa uma nova abordagem para construir aplicações de IA generativa que utilizam informações específicas de uma empresa. Em vez de confiar apenas no conhecimento estático de um modelo de linguagem grande (LLM), a arquitetura RAG integra mecanismos de busca e recuperação de dados ao processo de geração de respostas. Isso é especialmente útil em cenários de atendimento ao cliente: imagine chatbots que buscam em bases de conhecimento corporativas por manuais, políticas ou dados de produtos, e então geram respostas contextualizadas e precisas para os clientes. Neste artigo técnico, voltado a desenvolvedores, engenheiros de dados e arquitetos de soluções, vamos dissecar como a arquitetura RAG funciona tecnicamente utilizando ferramentas da Microsoft Azure e OpenAI – como o Azure Cognitive Search, Azure OpenAI Service, vetorização com embeddings e armazenamento de dados no Azure (Blob Storage, Cosmos DB etc.). Abordaremos os componentes envolvidos, o fluxo de dados passo a passo e um exemplo prático de aplicação em atendimento ao cliente com busca semântica e geração de respostas personalizadas.
Visão Geral da Arquitetura RAG
A arquitetura RAG combina dois blocos fundamentais: Recuperação de informações relevantes e Geração de linguagem natural. Em termos simples, o processo funciona assim:
- Uma pergunta ou solicitação do usuário chega ao sistema (por exemplo, através de um chat ou assistente virtual).
- O sistema primeiro consulta uma base de conhecimento em busca de informações pertinentes à pergunta. Essa busca pode ser realizada de forma semântica, usando vetores de embeddings para encontrar trechos de texto relacionados à consulta mesmo que não haja correspondência exata de palavras-chave.
- Os resultados da busca (documentos ou trechos relevantes) são então fornecidos como contexto adicional para um modelo de linguagem (por exemplo, GPT-4 no Azure OpenAI) junto com a pergunta original.
- O LLM gera uma resposta em linguagem natural que combina sua capacidade de compreensão e geração com as informações recuperadas, produzindo uma resposta final altamente informativa e contextualizada para o usuário.
Em outras palavras, o RAG “augmented” significa que a resposta do modelo é enriquecida por informações externas recuperadas no momento da pergunta. Isso dispensa a necessidade de treinar ou atualizar o modelo de linguagem com dados proprietários; em vez disso, o conhecimento corporativo é mantido em bases de dados que podem ser consultadas em tempo real. Conforme a Microsoft descreve, na arquitetura RAG o modelo de linguagem pré-treinado é usado sem treinamento adicional, gerando respostas que são complementadas pela informação obtida do mecanismo de busca.
Componentes Principais da Solução RAG
Vamos detalhar os principais componentes e serviços envolvidos ao implementar uma arquitetura RAG usando ferramentas Azure e OpenAI:
Azure Cognitive Search (Azure AI Search): Serviço de busca inteligente na nuvem Azure que atua como o sistema de recuperação de informações. Ele permite indexar documentos de diversas fontes e realizar consultas de alta relevância, incluindo recursos de busca semântica e vetorial. O Azure Cognitive Search oferece infraestrutura escalável para indexação e pesquisa, com a segurança e confiabilidade do Azure. Em um cenário RAG, ele funciona como o “cérebro de busca” que encontra os conteúdos mais relevantes na base de conhecimento corporativa para responder a cada pergunta.
- Base de Conhecimento (Dados em Azure Blob/Cosmos DB): Conjunto de documentos e informações da empresa que serão utilizados para responder perguntas. Esses dados podem incluir manuais de produto, artigos de help desk, FAQs, registros de chamados anteriores, políticas internas, entre outros. Eles podem estar armazenados em diversas fontes no Azure – como arquivos PDF em um Azure Blob Storage, documentos em SharePoint, registros em bancos de dados SQL ou NoSQL (por exemplo, Azure Cosmos DB), etc. O Azure Cognitive Search pode conectar-se a essas fontes para indexar todo o conteúdo, estruturado ou não, usando conectores disponíveis. Durante a indexação, o serviço extrai texto dos documentos, opcionalmente aplica enriquecimento cognitivo (OCR, tradução, etc. se configurado) e cria um índice pesquisável. Com o suporte a vetores, cada documento ou trecho também pode ter um vetor de embedding associado para busca semântica.
- Vetorização e Embeddings: Mecanismo que converte textos (tanto as perguntas dos usuários quanto os documentos da base) em vetores numéricos de alta dimensionalidade, de forma que textos semanticamente similares fiquem próximos nesse espaço vetorial. No contexto Azure/OpenAI, podemos usar um modelo de Embedding do Azure OpenAI (por exemplo, baseado no embedding model Ada) para gerar esses vetores. Os vetores dos documentos são calculados e armazenados no índice do Azure Cognitive Search (ou em um vetor DB separado, conforme a arquitetura) e, no momento da consulta, o vetor da pergunta do usuário é comparado para encontrar os documentos com maior similaridade de coseno. Esse processo permite encontrar respostas relevantes mesmo que a formulação da pergunta não coincida exatamente com o texto dos documentos, proporcionando uma busca semântica muito mais eficaz do que a busca por palavras-chave tradicional.
- Azure OpenAI Service (Modelos de Linguagem): Serviço que oferece acesso a modelos avançados de linguagem (como GPT-3.5, GPT-4) hospedados na infraestrutura Azure. Aqui é onde ocorre a geração de respostas em linguagem natural. O Azure OpenAI é usado de duas formas na arquitetura RAG: (1) para gerar embeddings (como citado acima, usando endpoints de Embedding) e (2) para gerar o conteúdo textual da resposta através de prompts passados ao modelo GPT. O Azure OpenAI Service garante que essas capacidades de IA estejam disponíveis de forma escalável e segura na nuvem, podendo ser integradas facilmente às aplicações corporativas via API. Vale ressaltar que o LLM, nesse contexto, permanece não-treinado especificamente com os dados da empresa – ao invés disso, ele recebe os documentos recuperados pelo Azure Cognitive Search e os utiliza como referência para compor a resposta. Assim, obtemos o melhor dos dois mundos: a potência do GPT para entender e responder perguntas complexas combinada com o conhecimento atualizado e factual dos dados proprietários.
- Aplicação/Orquestrador: Camada de integração que coordena o fluxo entre os componentes acima. Pode ser uma aplicação web backend, uma função serverless (Azure Functions), ou mesmo uma ferramenta especializada como o LangChain ou Semantic Kernel. Essa camada recebe a pergunta do usuário, realiza as chamadas necessárias – primeiro ao Azure Cognitive Search para obter os documentos relevantes, depois ao Azure OpenAI para gerar a resposta – e então agrega o resultado para retornar ao usuário. Ela também pode tratar funcionalidades adicionais, como gerenciamento de contexto em conversas de múltiplos turnos, tratamento de segurança (ex.: autenticar usuários e garantir que a consulta só acesse dados que o usuário pode ver), pós-processamento da resposta (formatar, citar fontes), e integração com outras APIs (por exemplo, recuperar dados do perfil do cliente para personalizar a resposta).
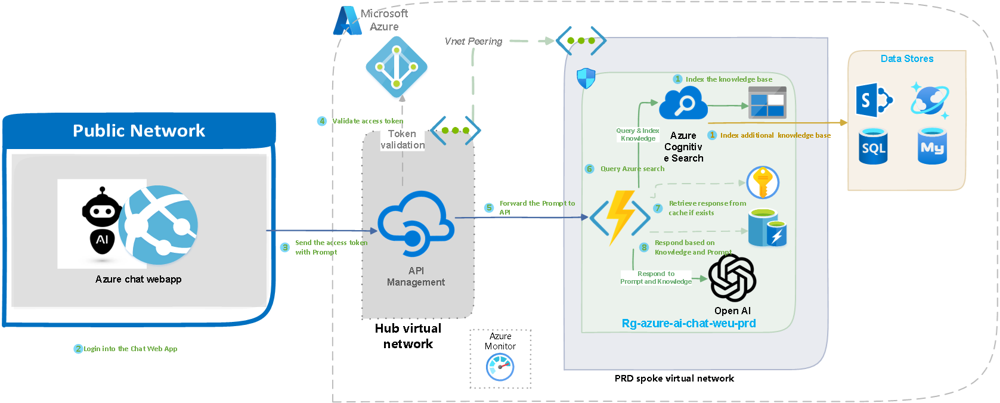
Exemplo de arquitetura técnica de uma solução RAG usando serviços Azure. À esquerda, um aplicativo web (Chat UI) no ambiente de rede pública recebe a pergunta do usuário. Em seguida, via API Management (centro), a requisição é encaminhada a um back-end na rede interna (hub virtual). Este orquestrador realiza uma busca no Azure Cognitive Search (lado direito) que indexa a base de conhecimento corporativa (SharePoint, SQL, Azure Storage etc.). Os documentos relevantes encontrados (chunks) são enviados ao serviço Azure OpenAI (modelo GPT) para compor a resposta final, que então retorna ao aplicativo web para o usuário. Todo o fluxo é monitorado pelo Azure Monitor, e componentes como Azure Active Directory garantem segurança (por exemplo, validação de token do usuário).
Fluxo de Dados e Funcionamento Detalhado
Com os componentes mapeados, vamos seguir o percurso de uma requisição dentro da arquitetura RAG, passo a passo, para entender a interação entre Azure Cognitive Search e Azure OpenAI no contexto de atendimento ao cliente:
- Pergunta do Usuário (Entrada) – O cliente faz uma pergunta através do canal de atendimento (um chat no site, Microsoft Teams, WhatsApp ou outro canal integrado). Por exemplo: “Meu produto X está com defeito, como aciono a garantia?”. Essa pergunta chega ao App UX, a interface do usuário do nosso sistema (pode ser um chatbot web, um assistente virtual, ou mesmo um agente virtual em um call center).
- Orquestração da Consulta – O aplicativo ou serviço de back-end recebe a pergunta e inicia o processo RAG. Nesta etapa, a aplicação pode gerar um embedding da pergunta (vetor representativo) usando o Azure OpenAI. Em seguida, a aplicação envia a consulta para o Azure Cognitive Search. Há duas possíveis abordagens aqui:
- Busca Vetorial: A pergunta em formato vetorial é comparada com os vetores dos documentos no índice para retornar os trechos mais semanticamente relevantes da base de conhecimento (por exemplo, o parágrafo do manual do produto que fala sobre garantia).
- Busca Semântica/Clássica: Alternativamente, o Azure Cognitive Search poderia fazer uma busca textual tradicional ou usando algoritmos semânticos internos para retornar documentos relevantes. Atualmente, a prática recomendada no RAG é a busca vetorial com embeddings, possivelmente combinada com filtros (por exemplo, buscar apenas em documentos da categoria “garantia”).
De qualquer modo, o resultado desta etapa é um conjunto dos melhores documentos ou snippets relacionados à pergunta do cliente, normalmente limitados aos top 3 ou top 5 resultados para manter concisão (você quer poucos trechos altamente relevantes devido ao limite de tokens que podem ser enviados ao modelo de linguagem).
- Composição do Prompt – De posse dos resultados da busca, o orquestrador agora constrói um prompt a ser enviado ao modelo de linguagem do Azure OpenAI. Esse prompt geralmente consiste em uma breve instrução ou contexto (por exemplo: “Você é um assistente de suporte que usa a base de conhecimento da empresa. Responda de forma educada e concisa.”), seguido pelos conteúdos recuperados (os textos dos documentos encontrados) e finalmente a pergunta do usuário. Essa técnica é chamada de prompt grounding, pois “aterra” o modelo nas informações fornecidas, para que a resposta seja sustentada por dados confiáveis.
- Geração da Resposta com Azure OpenAI – O prompt completo é enviado para o endpoint do modelo (por exemplo, GPT-4) no Azure OpenAI Service. O modelo processa a entrada, levando em conta tanto a pergunta quanto as referências contextuais dos documentos, e gera uma resposta em linguagem natural. Por exemplo, ele pode produzir: “Olá! Para acionar a garantia do produto X, você deve entrar em contato com nossa assistência técnica autorizada. Segundo o manual, é necessário apresentar a nota fiscal e o número de série do produto. O prazo de garantia do produto X é de 1 ano a partir da data de compra.” – note como a resposta hipotética incorpora detalhes que estavam em documentos da base de conhecimento (manual do produto, política de garantia).
- Devolução da Resposta ao Usuário – A aplicação recebe a resposta gerada e a encaminha de volta ao cliente através da interface de chat. O usuário então visualiza a resposta em poucos segundos após ter feito a pergunta, obtendo uma informação precisa e contextualizada. Opcionalmente, o sistema pode também exibir referências ou citações junto à resposta, indicando de qual documento ou artigo aquelas informações foram tiradas – isso aumenta a confiança e transparência (e é viável porque sabemos exatamente quais documentos foram recuperados na etapa de busca).
Durante todo esse fluxo, diversos benefícios técnicos ficam evidentes. Primeiro, o LLM nunca extrapola ou “inventa” fatos puramente do nada – ele se baseia nos dados recuperados, o que reduz drasticamente a chance de alucinações e aumenta a assertividade da resposta. Segundo, não foi necessário treinar o modelo GPT com nenhuma informação sobre garantia ou produto X previamente; o conhecimento foi incorporado dinamicamente via busca, o que economiza tempo e recursos (sem fine-tuning). Terceiro, a solução é escalável e atualizável: se amanhã mudar a política de garantia, basta atualizar o documento na base de conhecimento (por exemplo, substituir o PDF do manual no Blob Storage e reindexar) que o assistente virtual já passará a responder com a nova informação – não há dependência de re-treinar modelos, pois o RAG sempre busca os dados atualizados antes de responder.
Aplicação Prática em Atendimento ao Cliente
Vamos considerar um cenário concreto de fluxo de atendimento ao cliente automatizado usando RAG:
- Contexto: Uma empresa de comércio eletrônico implementa um chatbot de suporte ao cliente no seu site usando Azure Cognitive Search e Azure OpenAI. A empresa possui uma vasta base de conhecimento: artigos de ajuda, perguntas frequentes, manuais de produtos vendidos, políticas de troca e devolução, e até dados específicos de clientes (por exemplo, histórico de pedidos) em seus sistemas internos.
- Consulta do Cliente: Um cliente acessa o chat e pergunta: “Oi, fiz um pedido semana passada e não recebi confirmação. Como verificar se meu pedido foi registrado?”.
- Busca Semântica: O backend do chatbot recebe essa pergunta e imediatamente transforma-a em um vetor de embedding com um modelo OpenAI. Em seguida, faz uma consulta vetorial no índice do Azure Cognitive Search, que está povoado com documentos de suporte (incluindo talvez um artigo “O que fazer se não recebeu confirmação do pedido” e instruções do sistema de pedidos). O Azure Cognitive Search retorna, por exemplo, um trecho de um FAQ que diz: “Se você não recebeu a confirmação do pedido por e-mail, verifique a pasta de spam. Você também pode rastrear o status do pedido na área do cliente em nosso site, na seção ‘Meus Pedidos’.” e um procedimento interno sobre verificação de pedidos.
- Geração de Resposta: Com esses conteúdos em mãos, o sistema monta o prompt e envia ao Azure OpenAI (modelo GPT-3.5 Turbo, por exemplo). O modelo então produz uma resposta ao cliente mencionando os passos sugeridos (verificar spam, acessar área do cliente) e talvez adicionando: “Caso ainda tenha problemas, posso verificar aqui para você. Qual o número do seu pedido?”, simulando um atendimento personalizado.
- Interação Adicional: O cliente fornece o número do pedido; o sistema (via orquestrador) pode então, além do RAG, integrar com a API do banco de dados de pedidos para recuperar o status específico daquele pedido e utilizar o LLM para formatar a resposta: “Encontrei seu pedido: ele está confirmado e em separação. Você deverá receber o e-mail de confirmação em breve.”. Vemos aqui como o RAG pode se integrar a automações adicionais para fornecer respostas personalizadas, combinando conhecimento geral (FAQ) com dados específicos do cliente.
Do ponto de vista técnico, esse exemplo prático mostra a flexibilidade da arquitetura RAG. Ela permite encadear buscas e ações adicionais (ex: consulta a outros sistemas via APIs) junto com a geração de linguagem natural, oferecendo um atendimento robusto. Ferramentas como LangChain podem facilitar esse fluxo, coordenando “cadeias” de operações (buscar isto, chamar aquilo, então gerar resposta) dentro de um mesmo contexto de conversa.
Considerações Técnicas e Boas Práticas
Para implementar com sucesso uma solução RAG em produção, alguns pontos técnicos adicionais merecem atenção dos desenvolvedores e arquitetos:
- Estratégia de Indexação e Chunking: Dividir documentos extensos em chunks (pedaços) menores antes de indexar é crucial. Cada chunk deve conter conteúdo suficiente para ser útil, mas não tão grande a ponto de exceder limites de token quando vários são concatenados no prompt. Uma prática comum é usar chunks de algumas centenas de palavras, segmentados por tópicos ou headings lógicos do documento. O Azure Cognitive Search oferece pipelines de indexação e até habilidades cognitivas para extrair essas partes dos documentos. Também é importante atualizar periodicamente o índice conforme novos documentos são adicionados ou alterados (isso pode ser agendado, por exemplo, diariamente ou em tempo real dependendo da necessidade).
- Qualidade dos Embeddings: A escolha do modelo de embedding e a dimensionalidade do vetor influenciam a qualidade da busca vetorial. Os modelos de embedding do OpenAI (como o text-embedding-ada-002) são geralmente eficientes e multilingues, o que é útil se sua base de conhecimento e perguntas envolvem português e talvez outros idiomas. Garanta também normalizar os textos (remover excesso de formatação, stopwords irrelevantes, etc.) antes de gerar os embeddings, para melhorar a correspondência semântica.
- Filtragem e Segurança dos Dados: Em um contexto corporativo, nem toda informação deve estar acessível a todos os usuários. Considere utilizar os recursos de filtros de segurança do Azure Cognitive Search, como filtros por etiqueta ou acl, para restringir documentos por usuário ou por departamento quando necessário. Por exemplo, o chatbot pode identificar o usuário logado e somente recuperar documentos que ele tem permissão de ver. Azure Cognitive Search e outros componentes Azure integram-se com Azure Active Directory para controle de acesso, e todo o sistema pode operar dentro de redes virtuais isoladas, garantindo segurança e compliance no manuseio dos dados.
- Desempenho e Cache: Apesar do Azure OpenAI ser bastante rápido dado o que realiza, a etapa de geração de texto ainda adiciona latência (geralmente alguns segundos por resposta, dependendo do tamanho do prompt e do modelo). Para melhorar tempo de resposta em perguntas comuns, uma técnica útil é implementar um cache. O exemplo de arquitetura que apresentamos incorpora um Azure Redis Cache que armazena respostas já geradas para consultas idênticas. Assim, se múltiplos usuários perguntarem algo muito similar (“como reemitir segunda via de boleto”), a primeira resposta pode ser reutilizada por um período de tempo, aliviando cargas desnecessárias no modelo. Mas cuide para invalidar ou expirar caches se a base de conhecimento for atualizada (para não servir respostas desatualizadas).
- Monitoramento e Telemetria: Utilize o Azure Monitor e Application Insights para rastrear o desempenho do seu sistema RAG. Métricas importantes incluem: tempo de busca, tempo de geração da resposta, tamanho dos prompts, taxa de acerto (possivelmente medindo quantas vezes o usuário ficou satisfeito ou não precisou escalar para um humano), além de custos de uso de cada serviço (para otimização contínua). Monitoramento ajuda a identificar gargalos – por exemplo, se a busca está retornando resultados pouco relevantes (podendo exigir melhor tuning dos índices ou das consultas) ou se o modelo às vezes falha em seguir as diretrizes esperadas (podendo exigir prompt engineering mais refinado).
- Escalabilidade: A arquitetura RAG se beneficia da escalabilidade nativa da nuvem. Azure Cognitive Search pode ser dimensionado para índices maiores ou maior throughput de consultas (basta escolher aSKU apropriada e replicar/particionar conforme necessário). O Azure OpenAI por sua vez permite escalonar instâncias de inferência conforme a demanda. Isso significa que a solução pode ser dimensionada para atender desde algumas centenas até milhares de consultas por segundo, se necessário, mantendo desempenho consistente globalmente. Essa escalabilidade elástica é uma grande vantagem de usar serviços gerenciados da Azure, especialmente para aplicações de atendimento ao cliente onde a demanda pode flutuar (imagine picos durante uma Black Friday ou lançamento de produto).
Conclusão
A implementação da arquitetura RAG com ferramentas Microsoft Azure e OpenAI oferece uma solução técnica elegante e poderosa para construir assistentes virtuais e chatbots avançados de atendimento ao cliente. Recapitulando, integrando Azure Cognitive Search e Azure OpenAI, conseguimos unir o melhor dos dois mundos: busca inteligente em dados corporativos + geração de linguagem natural de última geração. Do ponto de vista do desenvolvedor e arquiteto, a abordagem RAG elimina a necessidade de treinar modelos complexos com dados proprietários, ao mesmo tempo em que garante que as respostas do sistema estejam sempre baseadas em informações atualizadas e relevantes. Neste guia técnico, vimos como cada componente contribui para o todo – desde o armazenamento dos documentos em Blob/Cosmos e sua indexação, passando pela vetorização das consultas, até a orquestração final que entrega uma resposta ao usuário.
Em suma, a arquitetura RAG proporciona um atendimento automatizado mais preciso, contextualizado e confiável, capaz de escalar com a demanda e de se manter alinhado ao conhecimento atual da empresa sem esforços de re-treinamento de IA. Para a equipe técnica, isso significa menos preocupações com dados desatualizados no modelo e mais controle sobre as fontes de verdade usadas nas respostas. Com Azure e OpenAI, a Microsoft fornece os blocos prontos para construir essas soluções – permitindo que os desenvolvedores concentrem-se em personalizar a experiência e integrar com os processos de negócio. A automação inteligente no suporte ao cliente, viabilizada por RAG, é um passo significativo rumo a assistentes virtuais realmente úteis no dia a dia, e estar familiarizado com sua arquitetura capacita os profissionais de TI a liderarem essa transformação dentro de suas organizações.
Bibliografia
Fontes oficiais consultadas
Azure OpenAI Service (Modelos GPT, Embeddings, Segurança)
https://learn.microsoft.com/pt-br/azure/ai-services/openai/overview
Azure Cognitive Search (Buscas vetoriais, semânticas e segurança)
https://learn.microsoft.com/pt-br/azure/search/search-what-is-azure-search
Semantic Kernel (orquestração de agentes e prompts em RAG)
https://learn.microsoft.com/en-us/semantic-kernel/overview
Azure Blob Storage e Cosmos DB para dados não estruturados e vetoriais
https://learn.microsoft.com/pt-br/azure/storage/blobs/storage-blobs-introduction
https://learn.microsoft.com/pt-br/azure/cosmos-db/introduction
Visão geral sobre embeddings do OpenAI (text-embedding-ada-002)