

Data Lakehouse:
Um data lakehouse é um tipo de sistema de gerenciamento de dados que combina os recursos de um data lake e um data warehouse. Um data lake é um repositório centralizado que permite que as organizações armazenem todos os seus dados estruturados e não estruturados em qualquer escala. Um data warehouse é um sistema usado para geração de relatórios e análise de dados e é projetado para oferecer suporte a consultas e análises eficientes de dados.
Ele é projetado para fornecer o melhor dos dois mundos, permitindo que as organizações armazenem e gerenciem grandes quantidades de dados em um repositório centralizado, além de fornecer a capacidade de realizar análises e consultas complexas sobre esses dados. Isso é feito integrando os recursos de armazenamento e gerenciamento de um data lake com os recursos de consulta e análise de um data warehouse.
Um dos principais benefícios é sua capacidade de lidar com dados estruturados e não estruturados. Isso permite que as organizações armazenem uma ampla variedade de tipos de dados, incluindo texto, imagens, vídeos e muito mais, em um único local. Além disso, um data lakehouse pode lidar com dados de qualquer tamanho, tornando-o adequado para ambientes de big data.
Outro benefício importante é sua capacidade de oferecer suporte a consultas e análises em tempo real. Ao integrar os recursos de consulta e análise de um data warehouse com os recursos de armazenamento e gerenciamento de um data lake, um data lakehouse pode fornecer informações quase em tempo real sobre os dados de uma organização. Isso permite que as organizações tomem decisões baseadas em dados com mais rapidez e eficácia.
Na figura abaixo, vemos a comparação entre Data Warehouse, Data lake e Data Lakehouse:

No Databricks, podemos encontrar uma arquitetura hibrida onde adicionamos recursos de integração para prover os dados para visuazação e outros trabalhos que possamos realizar.

Utilizando Microsoft Synapse, encontramos uma arquitetura base para a aplicação deste conceito, onde podemos enxergar que a principal estrutura de orquestração está na camada de preparação que melhora de forma acentuada a velocidade do tratamento dos dados e a distribuição para a camada de consumo. Ma primeira imagem um visão macro e na segunda, todo o pipeline de dados sendo demonstrado.

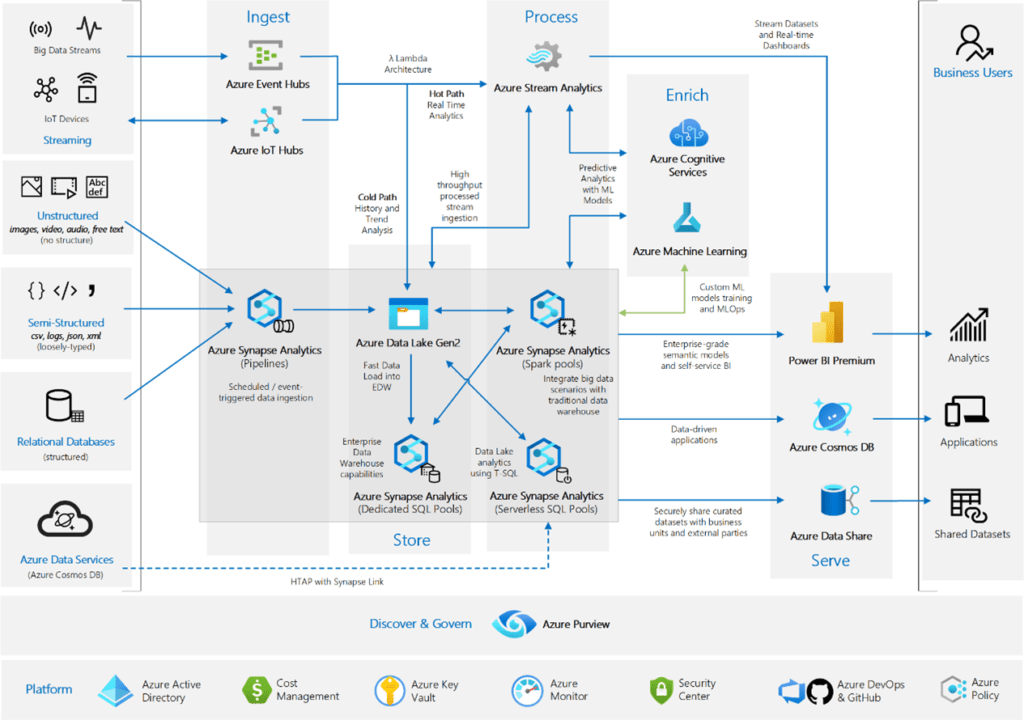
A seguir temos um pipeline de ingestão processado onde o Azure Data factory tem o papel de trazer os dados para a plataforma de Data Lakehouse:
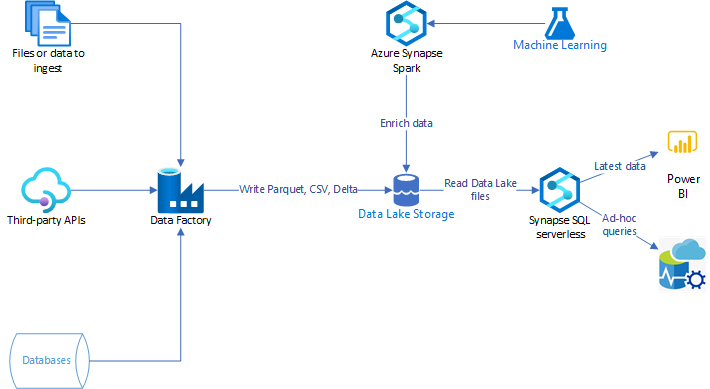
Em conclusão, um data lakehouse é uma ferramenta poderosa para gerenciamento e análise de dados. Ele fornece a capacidade de armazenar e gerenciar grandes quantidades de dados estruturados e não estruturados em um repositório centralizado, ao mesmo tempo em que oferece a capacidade de realizar análises e consultas complexas sobre esses dados quase em tempo real. Isso o torna adequado para ambientes de big data e organizações que buscam tomar decisões baseadas em dados de forma rápida e eficaz.
Para se aprofundar, alem das bibliografias recomendadas, a Databricks oferece alguns learning paths com as certificações em Data Lakehouse.
https://www.databricks.com/learn/certification
Fontes: Microsoft, Databricks, Ranjeet Srivastava, Mary Levins, Bill Inmon.