
Data Mesh – O que você precisa saber?
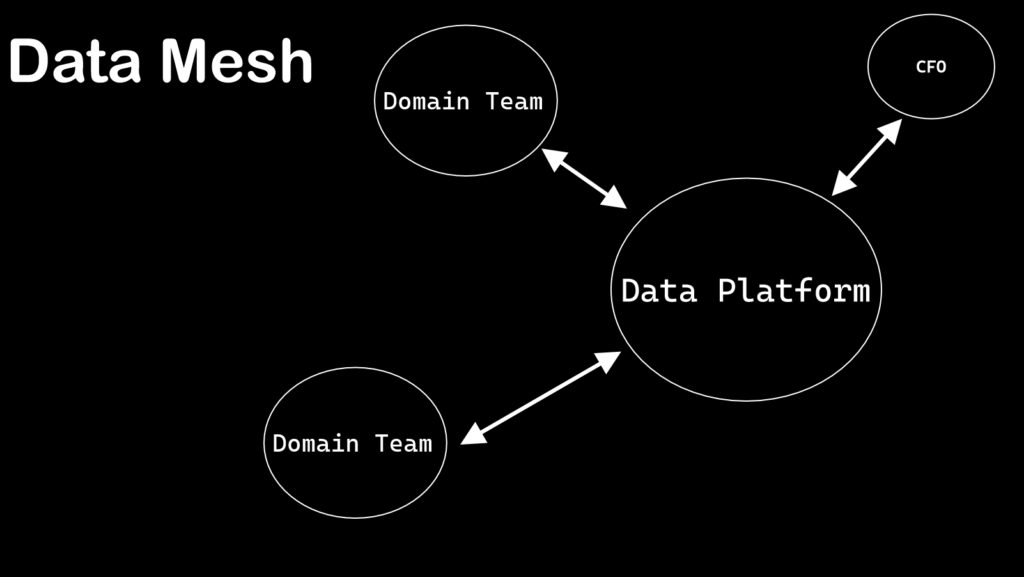
O que é Data Mesh?
Este termo foi introduzido no mundo de dados por Zhamak Dehghani em 2019 e é baseado em quatro princípios que regem este modelo de arquitetura de dados, são eles:
Propriedade de domínio:
Este princípio exige que as equipes de domínio assumam a responsabilidade pelos seus dados, de acordo com este princípio, os dados analíticos devem ser compostos por domínios, limitando-se os limites das equipes e ao contexto do sistema, seguindo a arquitetura de domínio, desta forma a equipe de dados central não tem mais propriedade sobre estes dados.
Dados como produto:
Considerando que existam consumidores para os dados além do domínio, a equipe de domínio responsável pelo dado é responsável por satisfazer as necessidades de outros domínios, fornecendo dados com garantia de qualidade, entendendo-se que estes dados devem ser tratados como quaisquer serviços ou microsserviços na organização.
Plataforma de Infraestrutura para self-serve data:
A plataforma de dados irá fornecer funcionalidades, ferramentas ou sistemas independentes do domínio para que se possa criar, executar ou manter o Data Product para todos os domínios.
Governança federada:
Para garantir que as regras organizacionais e regulamentos do setor sejam cumpridos, a área de governança deve prover uma padronização que deve ser seguida por todo o Data Mesh para garantir que estejam aderentes. Desta forma princípios de LGPD por exemplo devem ser aplicados seguindo estas normas padronizadas.
Por que você deve usar Data Mesh?
Vamos imaginar que sua empresa pretende fazer um evento especial para a Black Friday. E há poucas semanas dela, solicite ao time de analytics um relatório com informações relacionadas a um determinado produto ou preferência de clientes, por exemplo, baseado em uma região.
As organizações investiram em um datalake centralizado justamente pensando em impulsionar o seu negócio com base nas informações nela contidos.
A equipe de dados sempre quer responder a todas as perguntas rapidamente, no entanto, existem demandas que estão sendo desenvolvidas além de correções em pipeline de dados quebrados após alguma alteração em um banco de dados operacional, por exemplo.
Por conta de cenários como estes, a equipe de dados não pode lidar com a velocidade necessária para atender todos os domínios da empresa, e geralmente ela pode se tornar um gargalo.
Ao mesmo tempo para ter mais agilidade nos negócios, as organizações também investiram em arquiteturas orientadas a serviços e descentralizadas, orientadas a domínios. Mesmo com o conhecimento destes domínios a equipe de dados central é sobrecarregada para respondes a estes insights orientados por dados.
Com o crescimento da organização a situação tende a piorar, desta forma, a melhor saída para este problema é entregar a responsabilidade pelos dados para as equipes de domínio. Esta é a ideia por trás do Data Mesh, oferecer para o domínio a responsabilidade dos dados analíticos, uma arquitetura que permite que que as equipes realizem análises de dados entre domínios de forma semelhante a um microsservico ou API.
Como Projetar um Data Mesh?
Para criar uma arquitetura de Data Mesh, é importante frisar que as equipes de domínio vão realizar análise de dados entre domínios por conta própria. Cada equipe de domínio é responsável pelo seu dado operacional e analítico. Cada domínio cria seu Data Product a partir de seus dados analíticos com base na necessidade de outros domínios.
As equipes de domínio devem ser regidas pelas políticas globais, segurança, padrão de documentação da governança federada. Para que as equipes de domínio possam descobrir, entender e utilizar os Data Products, o time de dados deve garantir que a plataforma seja agnóstica a domínios, permitindo que as equipes de domínio analisem com eficiência e criem facilmente seus próprios Data Produtcs.
Uma equipe capacitadora deve orientar como o processo deve funcionar e direcionar os times de domínio como criar, analisar, modelar e manter os Data Products de maneira interoperáveis.
Quais são os componentes de uma arquitetura Data Mesh?
Data Product
Um Data Product geralmente é um conjunto de dados que pode ser acessado por outros domínios, semelhante a uma API. Por exemplo um relatório de vendas em uma tabela no Synapse Analytics ou um arquivo json em um Azure BLOB storage. Um Data Product pode ser também um relatório em PDF ou um modelo de Machine Learning que prevê a estimativa de vendas do próximo mês.
Para que o Data Product esteja visível ele deve ser descrito com metadados, incluindo informações como propriedade, contato, localização e acesso aos dados e frequência de atualização assim como uma especificação do modelo de dados.
Durante o ciclo de vida, a equipe de domínio deve ser responsável por garantir a qualidade destes dados, assim como sua disponibilidade e tratamento de duplicidade ou dados ausentes.
O Microsoft Purview pode ser usado para projetar um Data Product.
Governança federada
Esta equipe é formada por membros de todas as áreas que compõem o Data Mesh, concordando com as políticas globais que definem como os Data Products devem ser criados e mantidos.
As políticas globais fornecem padrões que podem definir como um determinado dado deve ser disponibilizado, como um CSV ou um JSON em um repositório em um Blob ou numa tabela no synapses por exemplo, além de documentar em uma wiki os conjuntos predefinidos de metadados, para cada Data Product.
Dentre as políticas globais, eles devem garantir que regras como LGPD devem ser atendidas para garantir as conformidades legais de cada setor.
Dados Analiticos
Normalmente os dados são ingeridos como dados brutos e não estruturados. Em etapas anteriores estes dados precisam ser limpos e estruturados em eventos que são pequenos e orientados aos domínios e entidades que representam objetos de negócios como artigos onde seu estado muda ao longo do tempo.
Estes dados podem muitas vezes serem importados manualmente por um arquivo CSV ou até mesmo por um e-mail. Os dados de outras equipes são integrados como dados externos.
O Data product publicado é resultado da agregação de eventos, entidades, manuais e dados externos.
Ingestão
Para que as equipes de domínio possam ingerir seus dados, é necessário que seu sistema de software seja projetado de acordo com uma arquitetura orientada a domínio.
Se a organização possuir um sistema de mensagens, como Kafka ou Event Hub por exemplo, os dados podem ser coletados e encaminhados para plataforma de dados por ferramentas de ingestão como Azure Data Factory, Databricks ou Azure Synapse, inclusive em tempo real ou NRT.
Com estes eventos bem definidos, os processos de ingestão vão garantir a limpeza dos dados e qualidade, excluindo duplicidades e a anonimização de dados sensíveis.
Quando não for viável alterar o software para garantir um processo de ingestão, é possível utilizar um CDC para transmitir diretamente estas informações para a plataforma de dados, assim como utilizar um processo de ETL ou ELT onde dados que não são disponibilizados em tempo real ou NRT são necessários para o Data Product.
Limpeza de Dados
Os processos de limpeza de dados são de responsabilidade das equipes de domínio e consistem em garantir que a qualidade de dados seja mantida, para isto ninguém melhor que a equipe de domínio que conhece bem seus dados para tratá-los.
Para alcançar um processo eficiente na limpeza de dados, alguns pontos precisam ser garantidos:
Estruturação: transformar dados NoSQL ou semiestruturados em modelos analíticos como por exemplo, extrair campos de um JSON.
Mitigação: prover consistência de informações quando os dados forem alterados, por exemplo, preencher valores nulos com padrões sensatos.
Desduplicação: remover todas as entradas duplicadas.
Completude: Certifique-se de que os dados contenham períodos acordados, mesmo quando houver problemas técnicos durante a ingestão.
Corrigir outliers: identificar e corrigir dados inválidos gerados por meio de bugs.
Usualmente no ambiente Azure processos após mapeamento pelo Purview são processados por Azure Data Factory, Azure Synapses ou Databricks, executando rotinas que garantam a limpeza de dados e sua qualidade.
Analytics
As equipes de domínio agregam seus dados analíticos como Data Products que são relevantes aos outros domínios.
Por meio de notebooks como databricks ou synapses analytics, as equipes de domínio realizam consultas analíticas para investigar e montar seus modelos.
A visualização de dados pode se dar por meio de ferramentas como Power BI, onde podemos enxergar de maneira visual quaisquer tendencias ou anomalias.
A criação de modelos analíticos mais avançados pode ser feita por ferramentas como Synapses ou Databricks, que por meio de linguagens como Python, Scala ou R, e bibliotecas especificas, os cientistas de dados podem gerar seus modelos estatísticos.
Plataforma de Dados
A plataforma de dados funciona como um Hub que oferece suporte para um autoatendimento a organização para que os times de domínio possam criar seus Data Products.
Cada equipe de domínio recebe sua própria área isolada, com a preparação para ingestão, consulta, armazenamento e visualização dos dados.
O Catálogo de dados deve ser criado, repositórios git, e quaisquer ferramentas que garantam dentro da organização o processo de criação de um pipeline de dados, uma das responsabilidades da plataforma de dados é combinar com eficiência todas as ferramentas que suportam estes pipelines e garantir que os processos sejam executados.
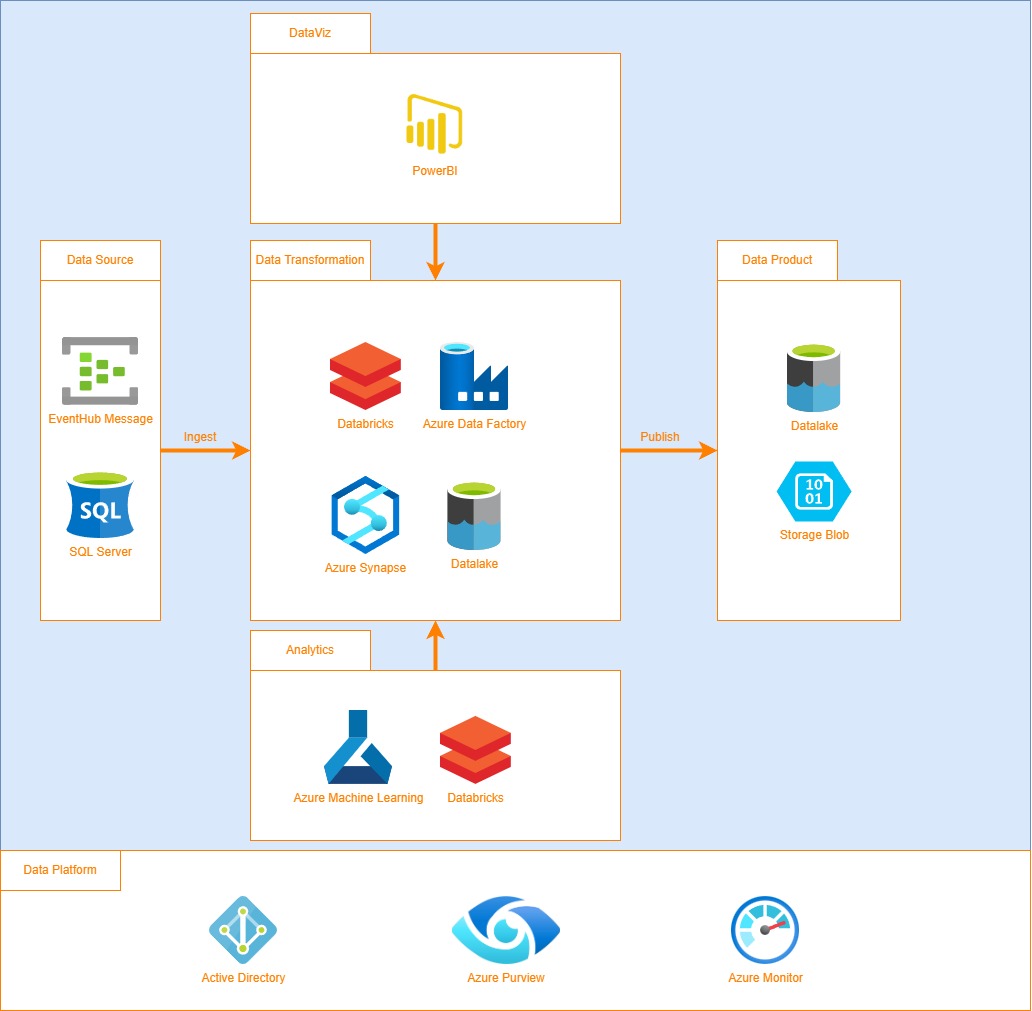
Arquitetura Data Mesh no Microsoft Azure
Conclusão
O conceito de Data Mesh é relativamente novo, como dito no início e de onde foi minha fonte para produção deste conteúdo, Zhamak Dehghani desenvolveu o conceito em 2019.
Para alcançar este nível de Big Data numa empresa, é muito importante que esta esteja com um grau de maturidade em dados alto. Pois processos de governança, segurança e qualidade devem estar implantados e eficientes para a organização.
Todas as organizações buscam além de qualidade uma velocidade na resposta dos dados para tomada de decisão estratégica.
Para isto é fundamental que estas empresas se tornem data driven, evangelizem os dados em todas as unidades de domínio desta organização, amadureça estes processos, com analytics estruturado, DataOps e uma governança de dados eficiente. O caminho não é curto, mas com estes pontos atendidos, o sucesso da implantação de Data Mesh na empresa é inevitável.
Fonte: O’Reilly – Data Mesh, Zhamak Dehghani, 2019.